|
Mariya I. Vasileva My name is Mariya, and I am a Senior Research Scientist at Meta Superintelligence Labs, where I study multimodal model behavior with a focus on visual reasoning, safety and alignment, and scalable evaluation of frontier models. Prior to my current role, I was an Applied Scientist at Amazon AWS, where I developed auditing methodologies for machine learning and computer vision systems in sensitive, high-impact settings, including multimodal foundation and generative models used in large-scale deployment. I have spent several years in industry research working on a broad range of vision and multimodal areas, including image and video generative models, visual recommender engines, 2D-to-3D human body shape and pose modelling, synthetic data generation for efficient training of foundation models at scale. I obtained my PhD in Computer Science from the University of Illinois at Urbana-Champaign under the advisorship of professor David A. Forsyth, where I researched problems in vision and language, visual search and retrieval, and applications of computer vision in the fashion domain. If you’re curious about my work, interested in collaborating, or want to share any thoughts or suggestions, please reach out! I’m always happy to connect. If you'd rather leave anonymous feedback, you're welcome to do so here. |


|
Updates
|
ResearchMy research focuses on vision and language learning in large-scale multimodal systems, with an emphasis on visual reasoning. A central pillar of my work is evaluation science for domain-specific and frontier models, encompassing representation learning, benchmark design, large-scale evaluation, and the use of synthetic data to probe model capabilities — particularly their performance on long-horizon, long-tail, and agentic tasks. Across these projects, a core theme has been multimodal safety, trust, and alignment, studied empirically through scalable oversight and systematic evaluation of vision–language understanding, reasoning, and model behavior across the full model lifecycle. |
|
|
Polyvore Outfits Dataset
Benchmark dataset page The Polyvore Outfits Dataset is a large-scale fashion dataset curated by real users on the Polyvore platform. Each outfit consists of manually constructed combinations of items that go well together, reflecting authentic human styling choices rather than synthetically or algorithmically generated sets. This human-driven curation captures implicit knowledge of color harmony, stylistic coherence, and garment compatibility, making the dataset well suited for research in similarity and compatibility learning, visual search and retrieval, recommendation systems, and multimodal reasoning. As a result, the dataset has been widely adopted in research across computer vision, recommendation systems, and multimodal learning. |

|
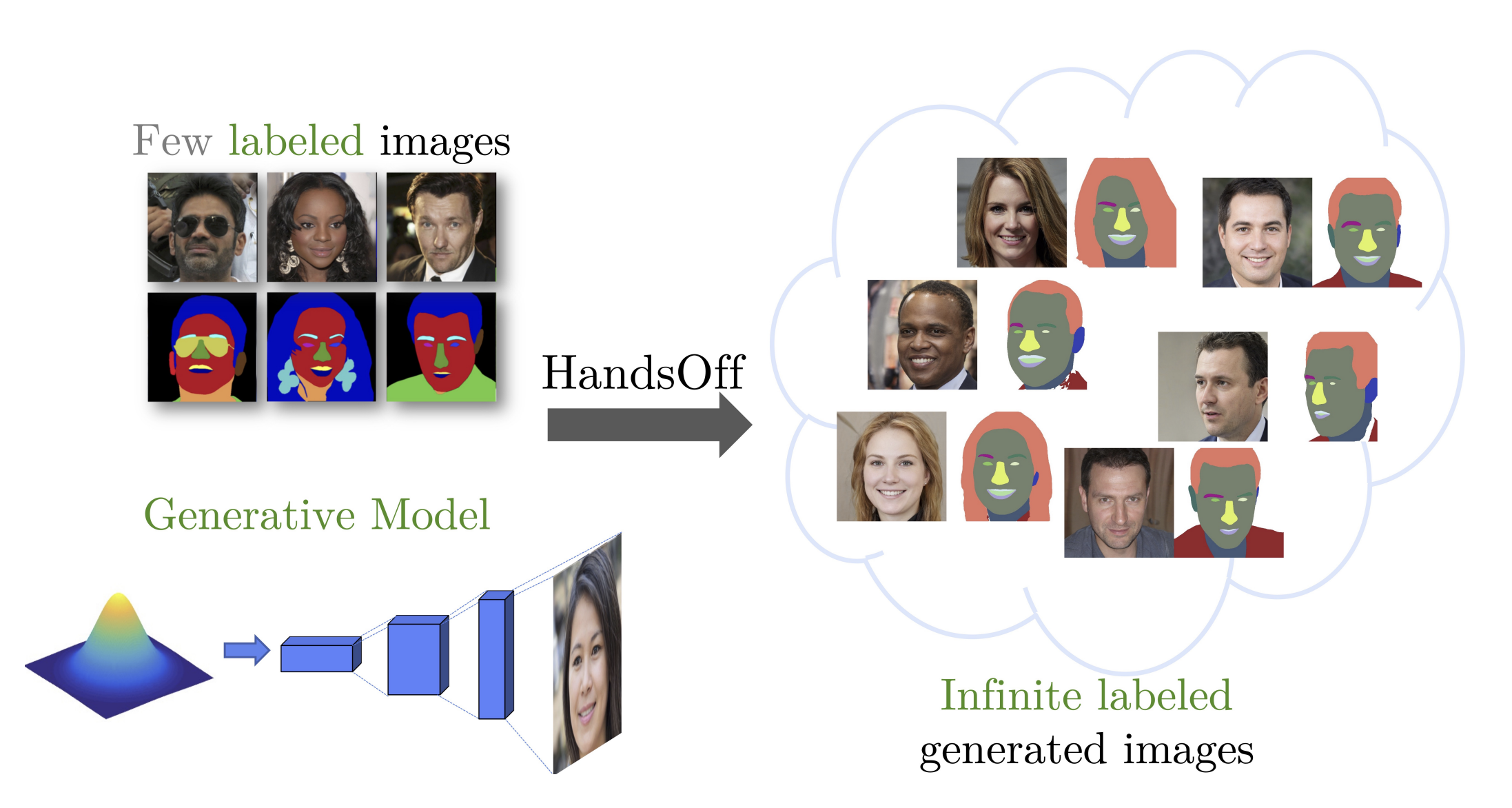
HandsOff: Labeled Dataset Generation with No Additional Human Annotations
Austin Xu, Mariya I. Vasileva , Achal Dave, Arjun Seshadri CVPR, 2023 (Highlight) project page / code / arXiv Recent work leverages the expressive power of generative adversarial networks (GANs) to generate labeled synthetic datasets. These dataset generation methods often require new annotations of synthetic images, which forces practitioners to seek out annotators, curate a set of synthetic images, and ensure the quality of generated labels. We introduce the HandsOff framework, a technique capable of producing an unlimited number of synthetic images and corresponding labels after being trained on less than 50 pre-existing labeled images. Our framework avoids the practical drawbacks of prior work by unifying the field of GAN inversion with dataset generation. We generate datasets with rich pixel-wise labels in multiple challenging domains such as faces, cars, full-body human poses, and urban driving scenes. Our method achieves state-of-the-art performance in semantic segmentation, keypoint detection, and depth estimation compared to prior dataset generation approaches and transfer learning baselines. We additionally showcase its ability to address broad challenges in model development which stem from fixed, hand-annotated datasets, such as the long-tail problem in semantic segmentation. |
|
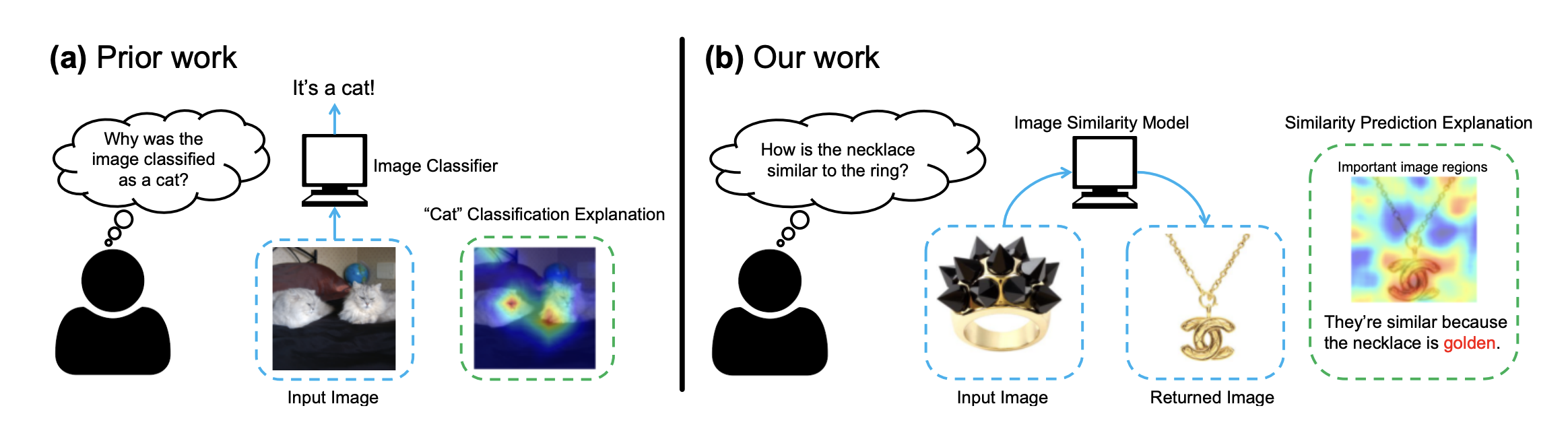
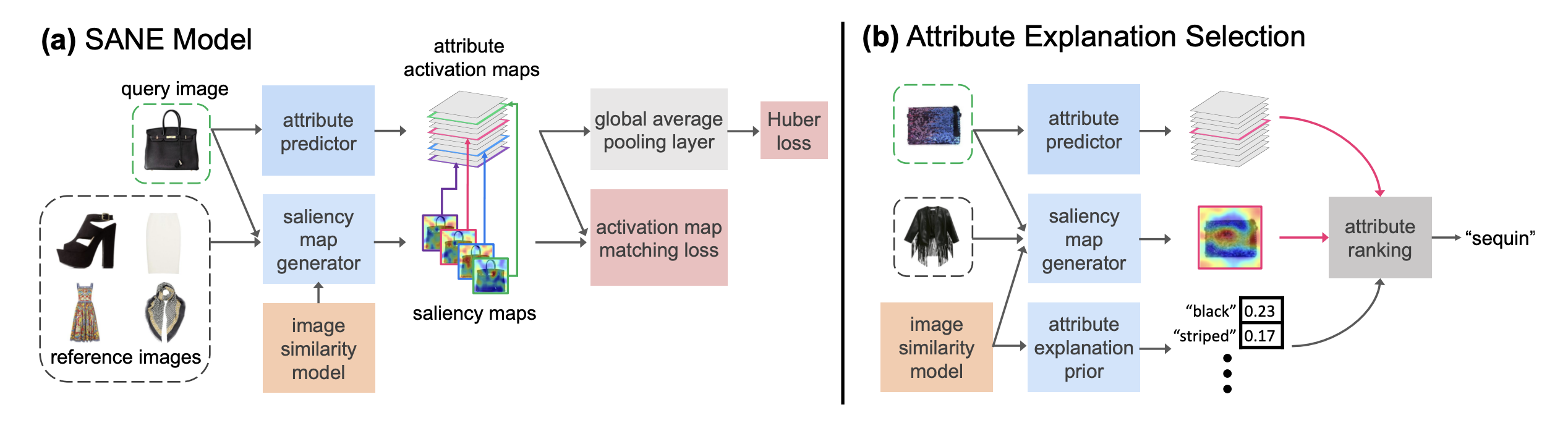
Why do These Match? Explaining the Behavior of Image Similarity Models
Bryan A. Plummer*, Mariya I. Vasileva*, Vitali Petsiuk, Kate Saenko, David A. Forsyth ECCV, 2020 code / arXiv Explaining a deep learning model can help users understand its behavior and allow researchers to discern its shortcomings. Recent work has primarily focused on explaining models for tasks like image classification or visual question answering. In this paper, we introduce Salient Attributes for Network Explanation (SANE) to explain image similarity models, where a model’s output is a score measuring the similarity of two inputs rather than a classification score. In this task, an explanation depends on both of the input images, so standard methods do not apply. Our SANE explanations pairs a saliency map identifying important image regions with an attribute that best explains the match. We find that our explanations provide additional information not typically captured by saliency maps alone, and can also improve performance on the classic task of attribute recognition. Our approach’s ability to generalize is demonstrated on two datasets from diverse domains, Polyvore Outfits and Animals with Attributes 2. |

|
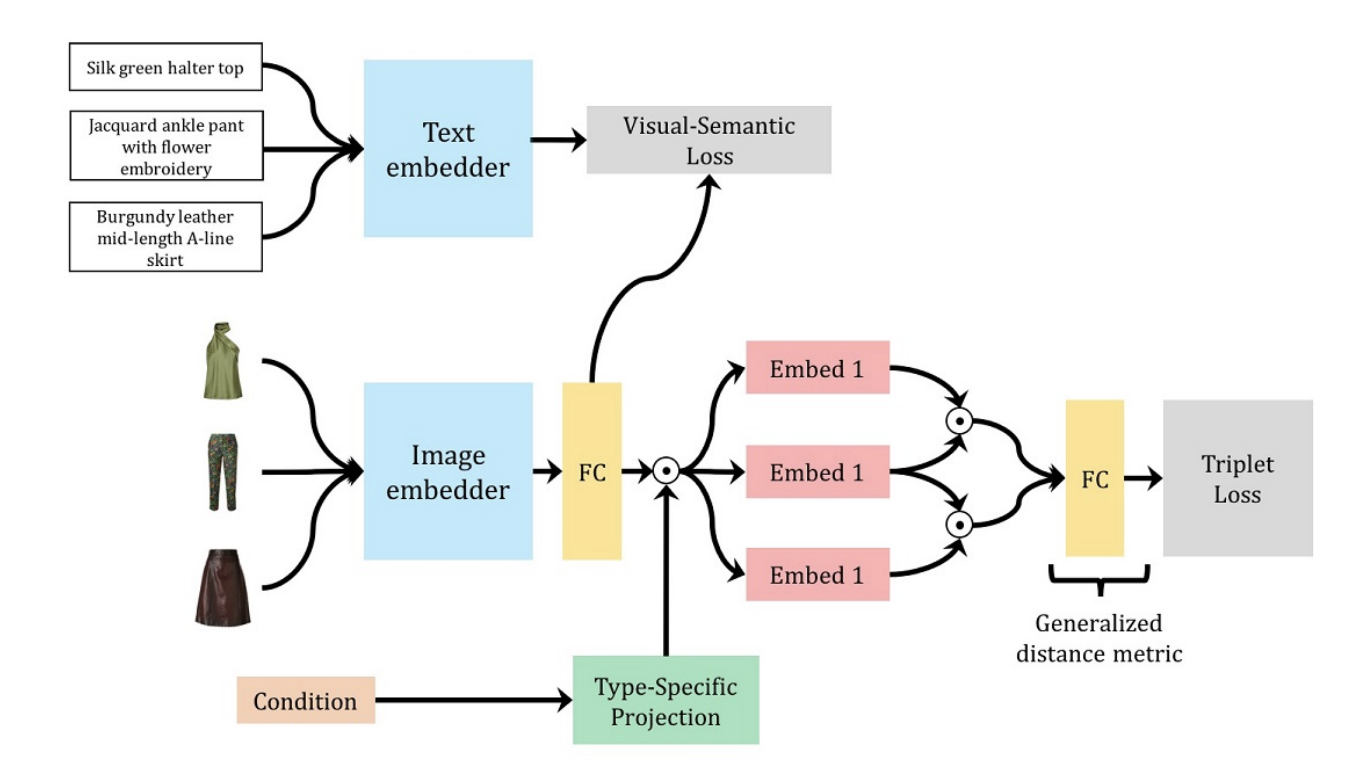
Learning Type-Aware Embeddings for Fashion Compatibility
Mariya I. Vasileva, Bryan A. Plummer, Krishna Dusad, Shreya Rajpal, Ranjitha Kumar, David A. Forsyth ECCV, 2018 code / arXiv Outfits in online fashion data are composed of items of many different types (e.g. top, bottom, shoes) that share some stylistic relationship with one another. A representation for building outfits requires a method that can learn both notions of similarity (for example, when two tops are interchangeable) and compatibility (items of possibly different type that can go together in an outfit). This paper presents an approach to learning an image embedding that respects item type, and jointly learns notions of item similarity and compatibility in an end-toend model. To evaluate the learned representation, we crawled 68,306 outfits created by users on the Polyvore website. Our approach obtains 3-5% improvement over the state-of-the-art on outfit compatibility prediction and fill-in-the-blank tasks using our dataset, as well as an established smaller dataset, while supporting a variety of useful queries |

|
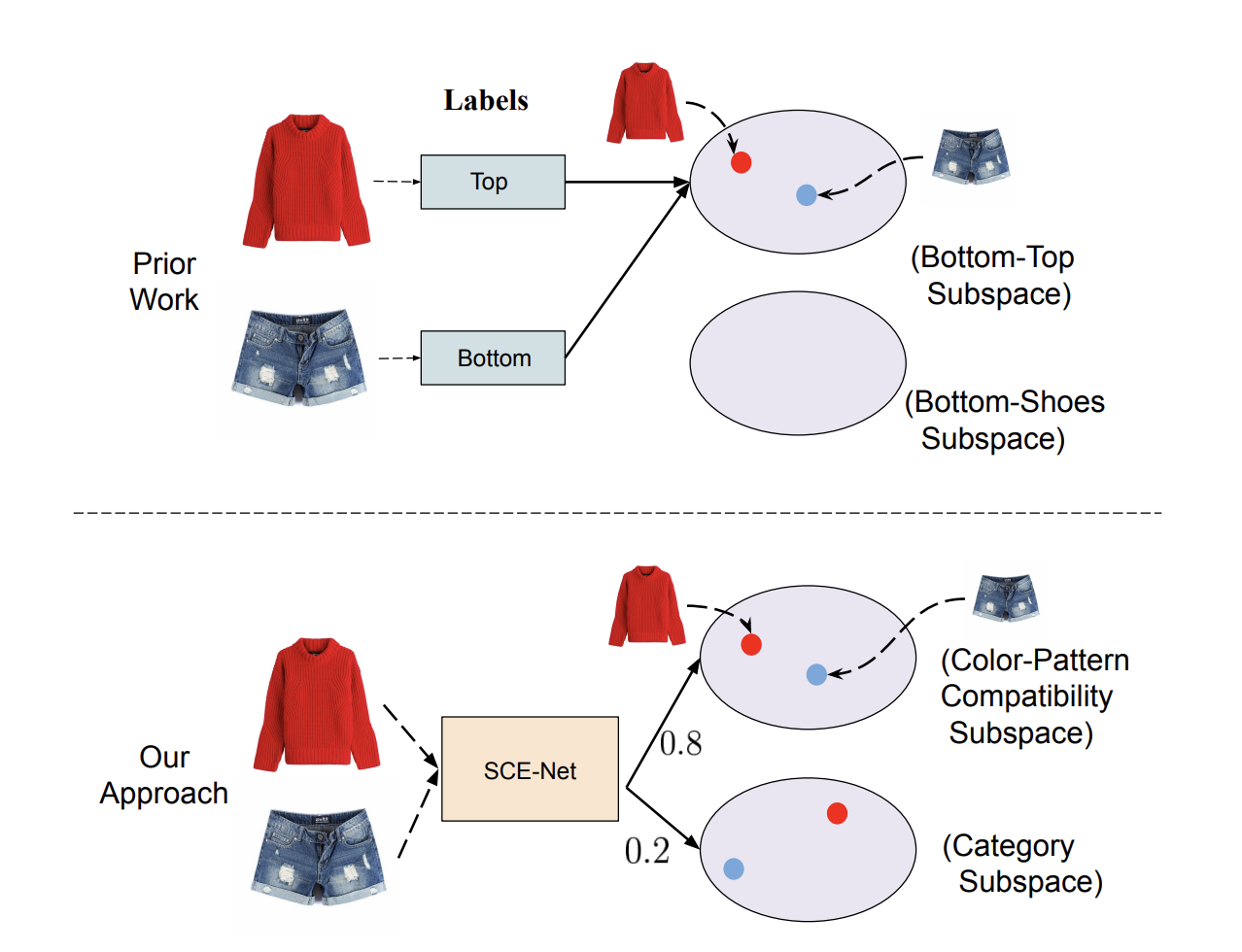
Learning Similarity Conditions Without Explicit Supervision
Reuben Tan, Mariya I. Vasileva, Bryan A. Plummer, Kate Saenko, David A. Forsyth ICCV, 2019 code / arXiv Many real-world tasks require models to compare images along multiple similarity conditions (e.g. similarity in color, category or shape). Existing methods often reason about these complex similarity relationships by learning condition-aware embeddings. While such embeddings aid models in learning different notions of similarity, they also limit their capability to generalize to unseen categories since they require explicit labels at test time. To address this deficiency, we propose an approach that jointly learns representations for the different similarity conditions and their contributions as a latent variable without explicit supervision. Comprehensive experiments across three datasets, Polyvore Outfits, Maryland-Polyvore and UT-Zappos50k, demonstrate the effectiveness of our approach: our model outperforms the state-of-the-art methods, even those that are strongly supervised with pre-defined similarity conditions, on fill-in-the-blank, outfit compatibility prediction and triplet prediction tasks. Finally, we show that our model learns different visually-relevant semantic sub-spaces that allow it to generalize well to unseen categories. |